Overview
Generate images directly in chat using AI models. Supports both generation from text prompts and iterative editing of existing images.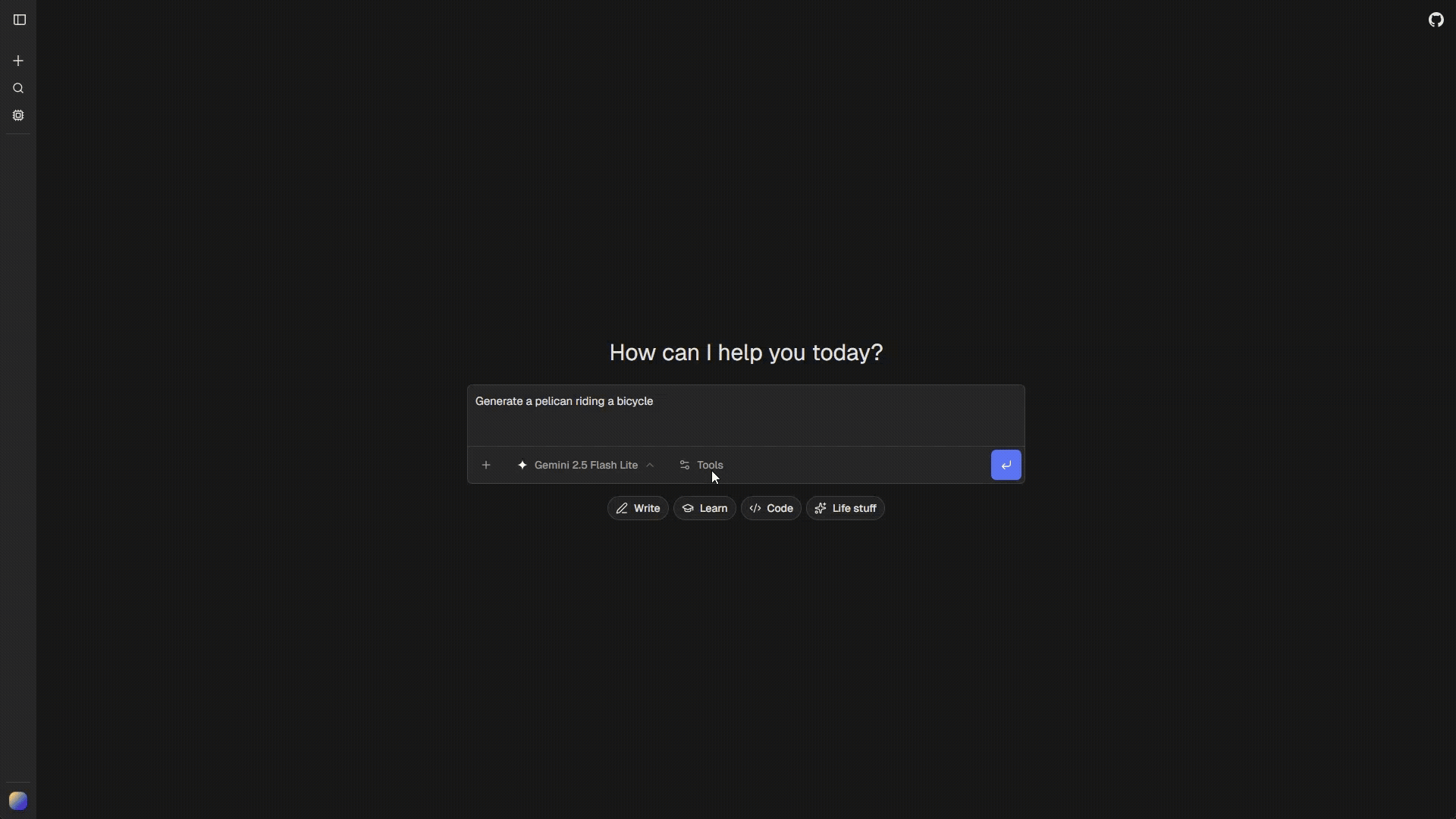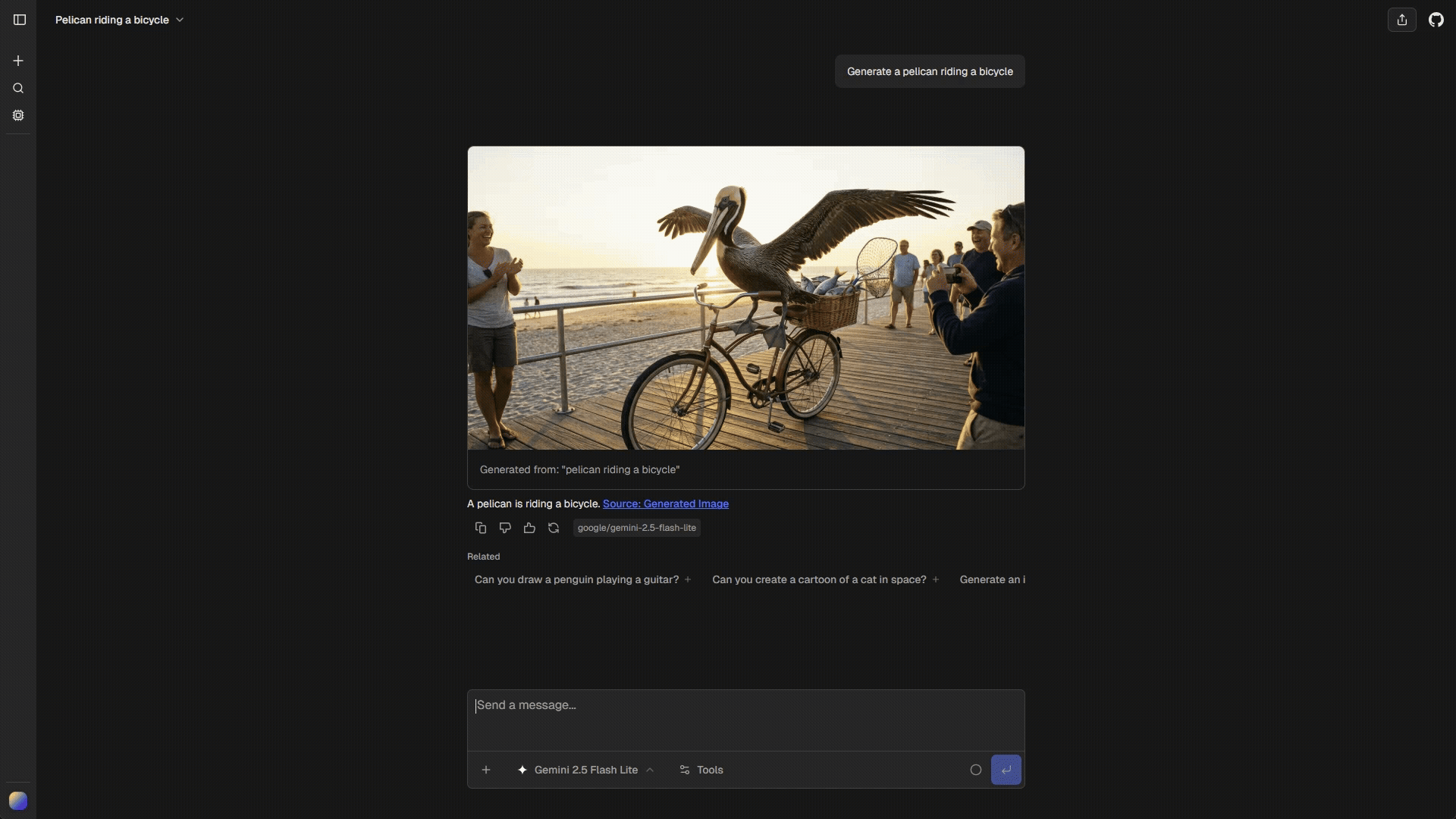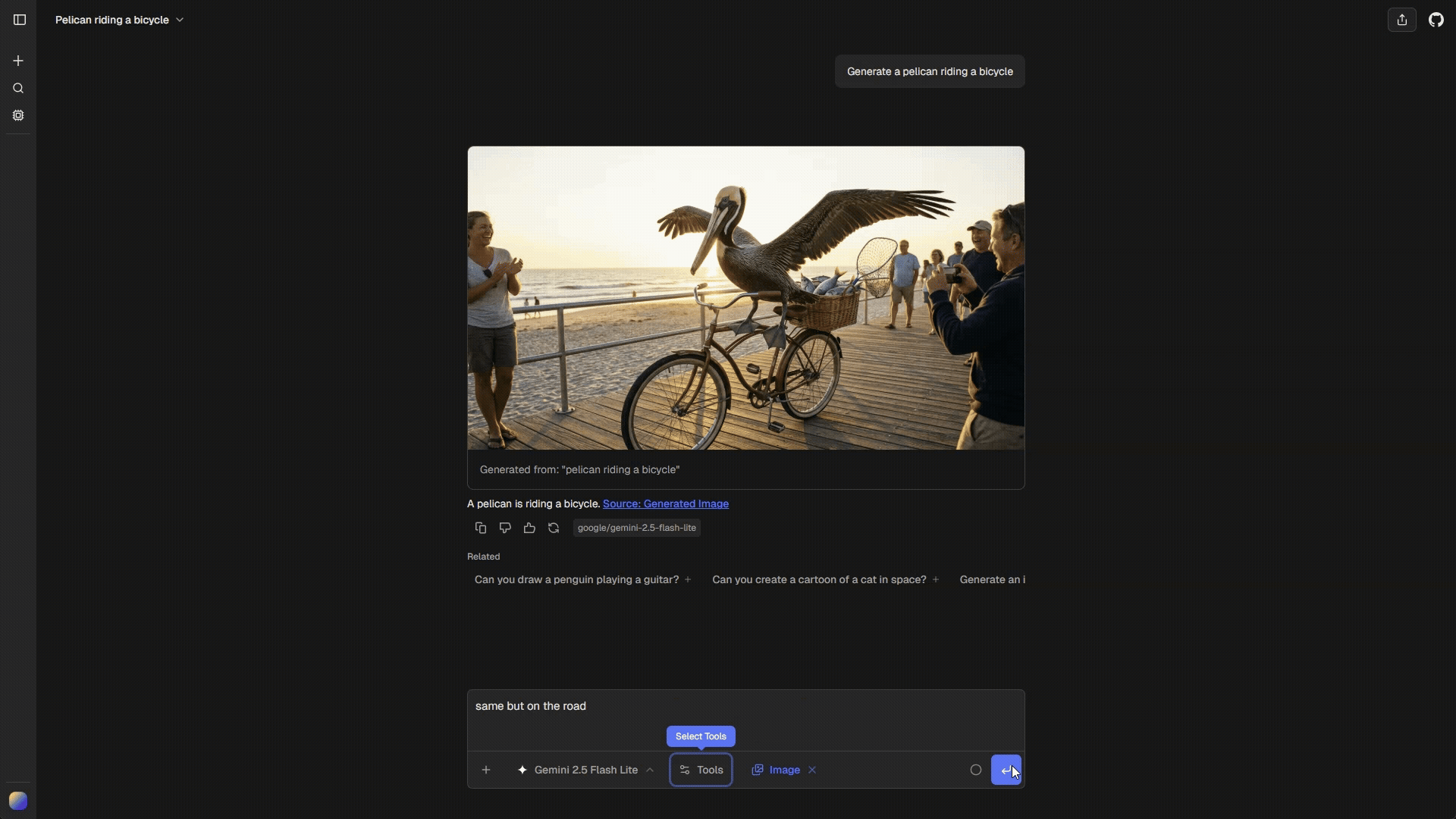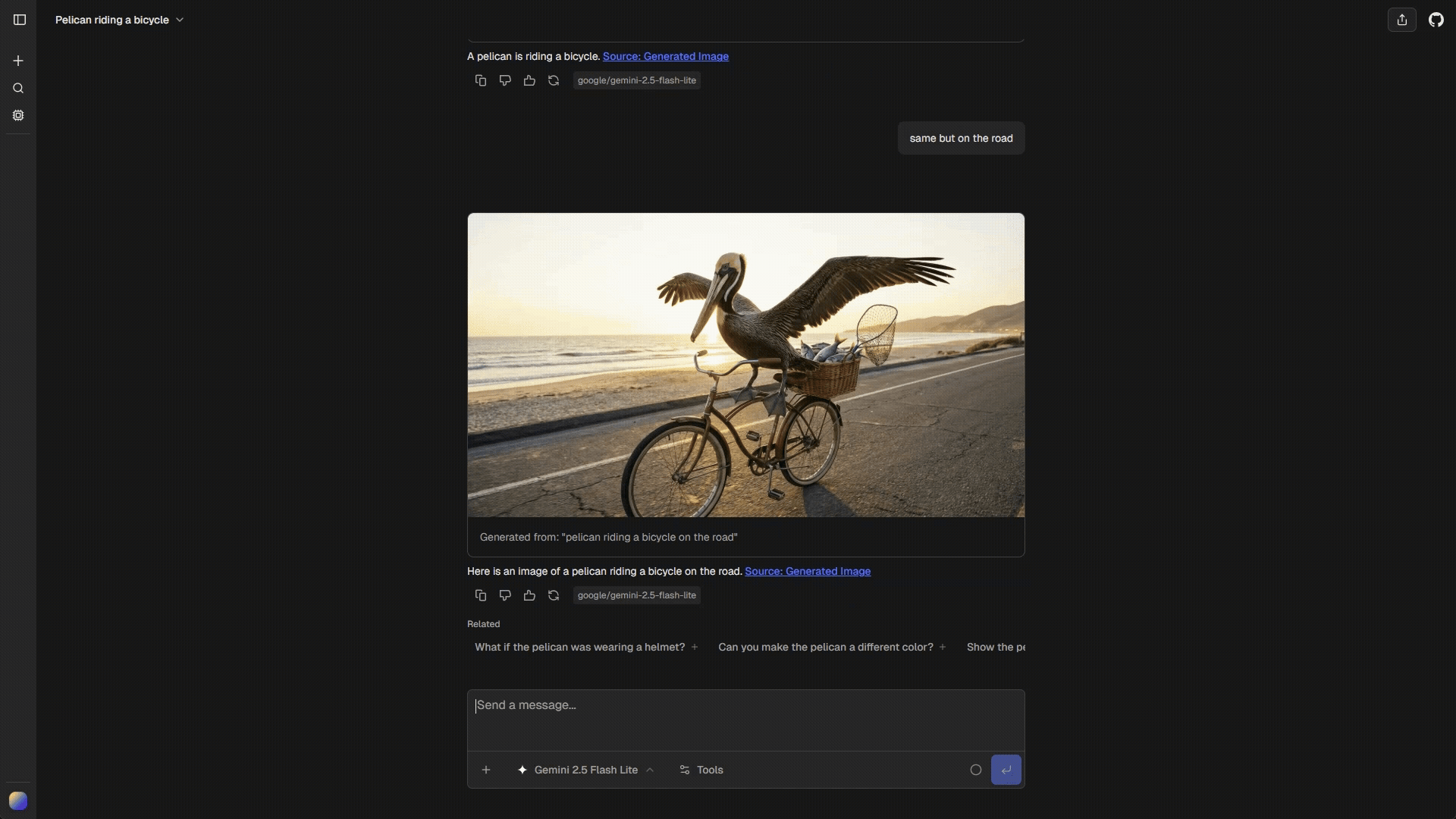
Quick Start
Toggle inchat.config.ts:
Image generation requires
BLOB_READ_WRITE_TOKEN since generated images are
uploaded to Vercel Blob storage.Modes
The tool operates in two modes based on context:| Mode | Trigger | Behavior |
|---|---|---|
generate | Text prompt only | Creates new image from scratch |
edit | Prompt + attachments or previous generation | Uses existing images as input |
Iterative Editing
Users can iterate on generated images without re-uploading. The system automatically tracks the last generated image in the conversation.How It Works
- Extraction: Before each request, the chat agent scans recent messages for the last generated image:
app/(chat)/api/chat/get-recent-generated-image.ts
- Injection: The extracted image is passed to the tool factory:
lib/ai/core-chat-agent.ts
- Edit mode: When
lastGeneratedImageexists, the tool fetches it and includes it as input:
lib/ai/tools/generate-image.ts
User Experience
- User: “Generate a sunset over mountains”
- AI: generates image
- User: “Add a lake in the foreground”
- AI: edits previous image (no re-upload needed)
Image Sources
Edit mode combines images from multiple sources:| Source | Description |
|---|---|
lastGeneratedImage | Most recent generated image in conversation |
attachments | User-uploaded images in current message |
Architecture
Follows the Tool Part pattern:Tool Output
UI States
| State | Shows |
|---|---|
input-available | Skeleton + “Generating image: “ |
output-available | Image + copy button + prompt |
Configuration
Image Model
chat.config.ts
Model Selection Logic
The tool supports two types of models:| Type | Description | Example |
|---|---|---|
| Image model | Standalone image generation models | google/gemini-3-pro-image |
| Multimodal | Language models with image generation capability | google/gemini-2.0-flash-exp |
resolveImageModel(selectedModel) in lib/ai/tools/generate-image.ts:
- If the user’s selected chat model supports image output (per app model registry,
model.output.image), use it - Otherwise, fall back to
config.ai.tools.image.default
Image Model vs Multimodal Generation
The tool uses different generation paths based on model type: Image model (generateImage from AI SDK):
- Uses standalone image models via
getImageModel() - Supports edit mode with image buffers as input
- Returns base64-encoded images
generateText with image output):
- Uses language models via
getMultimodalImageModel() - Passes images as URL references in message content
- Requires
responseModalities: ["TEXT", "IMAGE"]for Google models - Extracts generated image from response files